 DPoser-X: Diffusion Model as Robust
DPoser-X: Diffusion Model as Robust
3D Whole-body Human Pose Prior
Junzhe Lu1,*,
Jing Lin2,*,
Hongkun Dou3,
Ailing Zeng4,
Yue Deng3,
Xian Liu5,
Zhongang Cai6,
Lei Yang6,
Yulun Zhang7,
Haoqian Wang1,†,
Ziwei Liu2,†
1Tsinghua University, 2Nanyang Technological University, 3Beihang University,
4Independent Researcher, 5NVIDIA Research, 6SenseTime Research, 7Shanghai Jiao Tong University
* Equal contribution. † Corresponding authors.
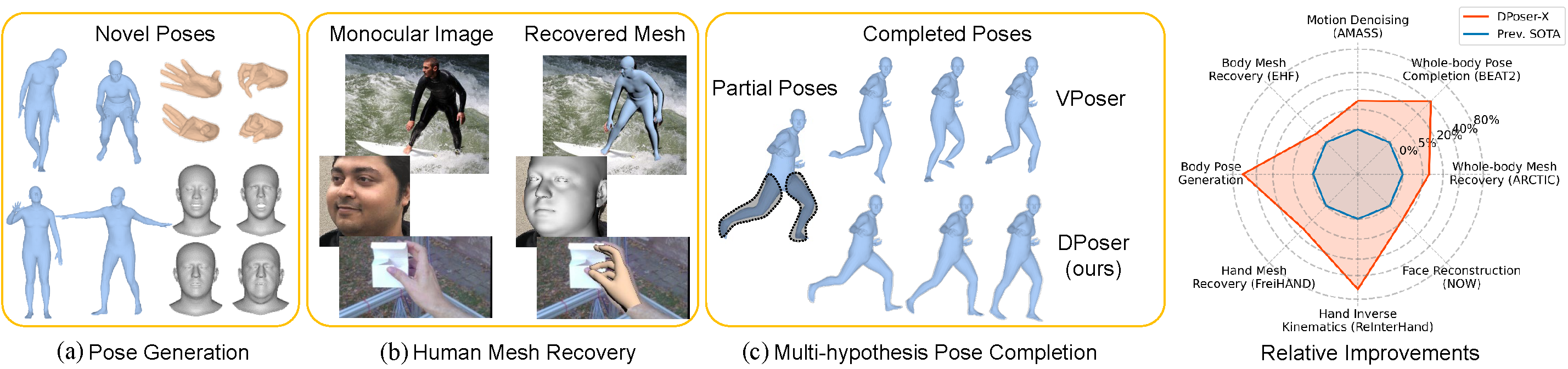
An overview of DPoser-X's versatility and performance across multiple pose-related tasks. Built on diffusion models, DPoser-X serves as a robust and adaptable prior for 3D whole-body human pose modeling. Shown are scenarios in (a) pose generation, (b) human mesh recovery, and (c) pose completion. With up to 61% improvement across 8 benchmarks, DPoser-X consistently outstrips existing priors like VPoser and NRDF, proving its superiority in tasks involving the human body, hand, and face.
Abstract
We present DPoser-X, a diffusion-based prior model for 3D whole-body human poses. Building a versatile and robust full-body human pose prior remains challenging due to the inherent complexity of articulated human poses and the scarcity of high-quality whole-body pose datasets. To address these limitations, we introduce a Diffusion model as body Pose prior (DPoser) and extend it to DPoser-X for expressive whole-body human pose modeling. Our approach unifies various pose-centric tasks as inverse problems, solving them through variational diffusion sampling. To enhance performance on downstream applications, we introduce a novel truncated timestep scheduling method specifically designed for pose data characteristics. We also propose a masked training mechanism that effectively combines whole-body and part-specific datasets, enabling our model to capture interdependencies between body parts while avoiding overfitting to specific actions. Extensive experiments demonstrate DPoser-X's robustness and versatility across multiple benchmarks for body, hand, face, and full-body pose modeling. Our model consistently outperforms state-of-the-art alternatives, establishing a new benchmark for whole-body human pose prior modeling.Demo Video
Methodology Overview
DPoser-regularized Optimization Framework
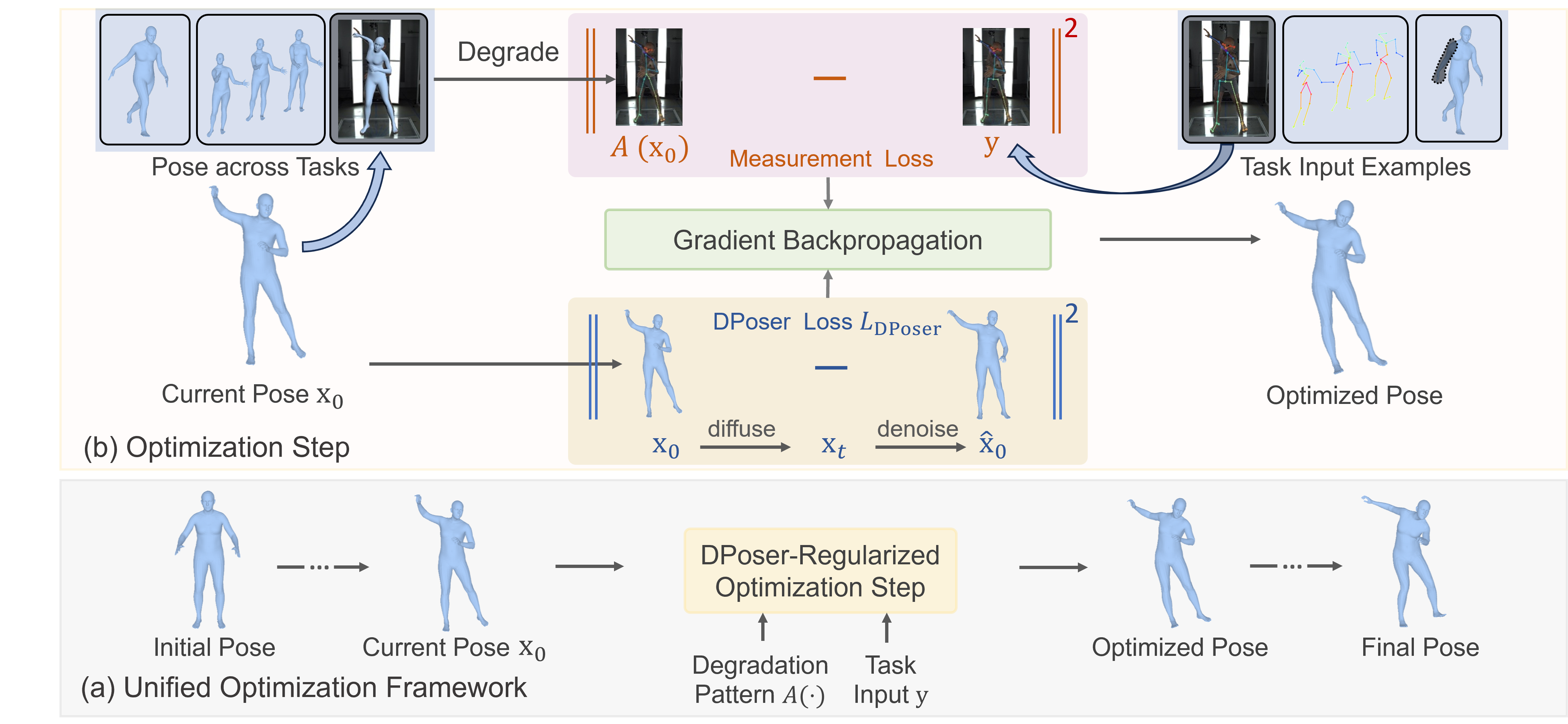
Overview of the DPoser-regularized optimization framework. Panel (a) shows the unified framework from initial to final poses through DPoser-regularized steps. Panel (b) details the optimization step: task inputs (e.g., 2D keypoints in human mesh recovery) and current poses are used to compute the measurement loss based on the degradation pattern $ \mathcal{A}(\cdot) $ (e.g., camera projection). Meanwhile, DPoser regularization introduces noise to the current pose and applies a one-step denoiser to compute $ L_{\text{DPoser}} $. Our DPoser regularization encourages the current pose towards a more plausible pose distribution.
Architecture and Training Strategy of DPoser-X
(a) Fused Whole-body Network: The DPoser-X architecture begins with frozen, pre-trained part-specific networks for the body, hands, and face. A separate fused module is then trained on top of these using whole-body datasets to learn the correlations and interdependencies between different body parts, such as the relationship between hand gestures and body posture during specific actions.
(b) Mixed Training Strategy: To improve generalization and prevent overfitting to limited whole-body data, DPoser-X employs a mixed training strategy. It utilizes a large corpus of part-only datasets (body, hand, face) by treating them as incomplete whole-body data and applying loss only to the available parts. To ensure the model can still predict complete poses, whole-body data is also used, sometimes with parts randomly masked, to train the network to fill in the missing information. This strategy results in the DPoser-X-mixed model, which balances realism with high diversity.
Body-only Tasks
Pose Generation
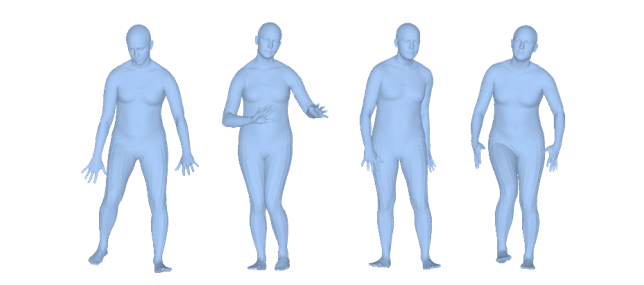

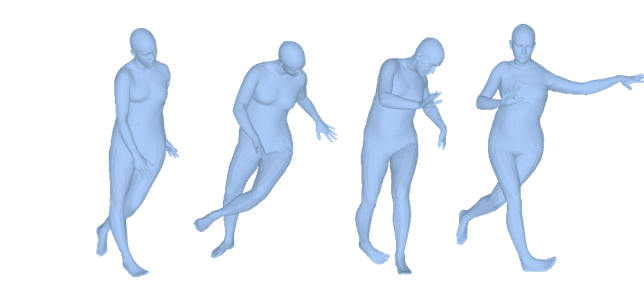

In body pose generation, DPoser generates visually diverse and realistic poses, indicating a well-learned prior distribution. In contrast, VPoser shows limited diversity due to its mean-centric nature, while GMM and Pose-NDF fall short in naturalism.
Pose Completion
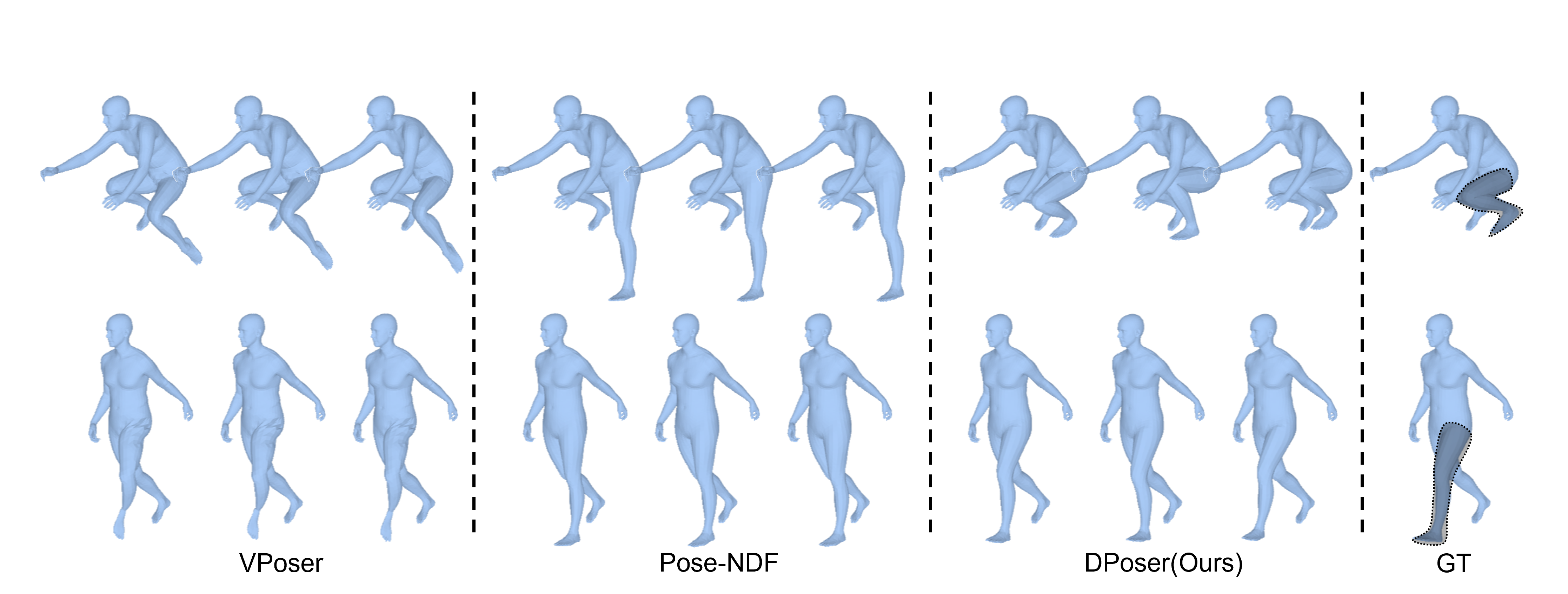
Left leg under occlusion.

Torso under occlusion.
In pose completion, DPoser is unique in its ability to provide multiple plausible solutions for partially observed poses, a challenge where competing methods often fall short due to limitations in generalization.
Human Mesh Recovery

Fitting from scratch.
Initialization with CLIFF.

EHF dataset

COCO dataset

3DPW dataset

UBody dataset
More examples on various datasets.
In Human Mesh Recovery (HMR), DPoser adeptly estimates poses from single images, achieving more natural poses. It can also refine initial pose estimations from models like CLIFF, achieving better alignment with images.
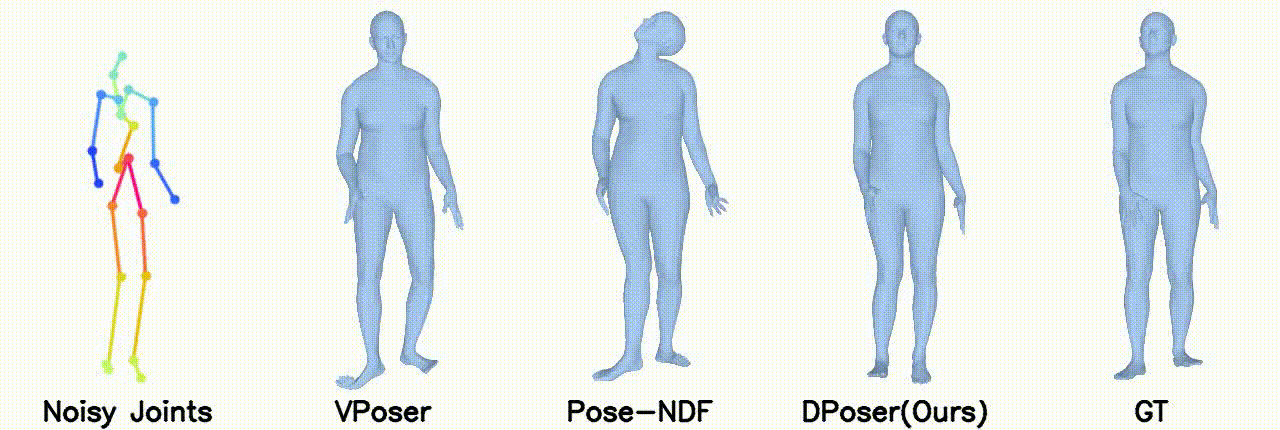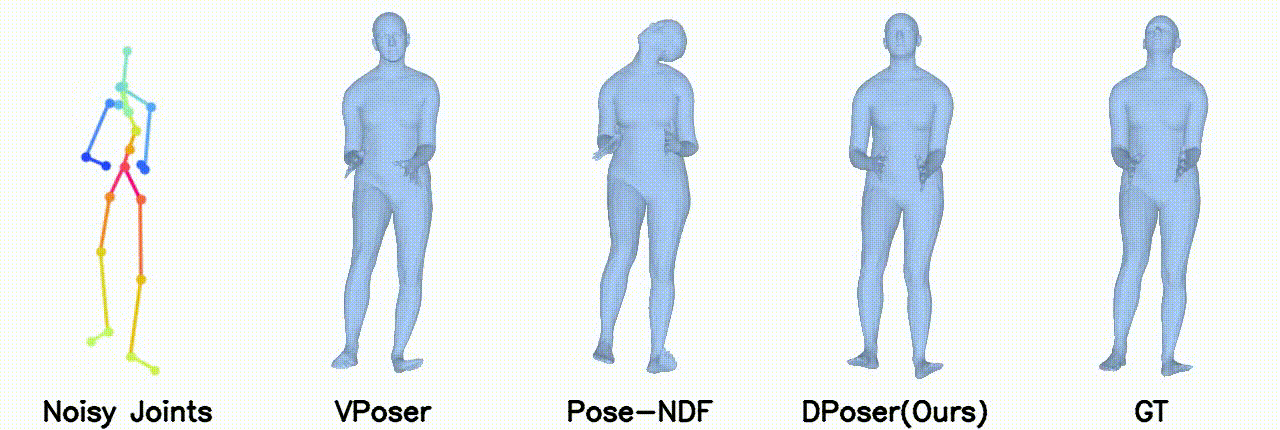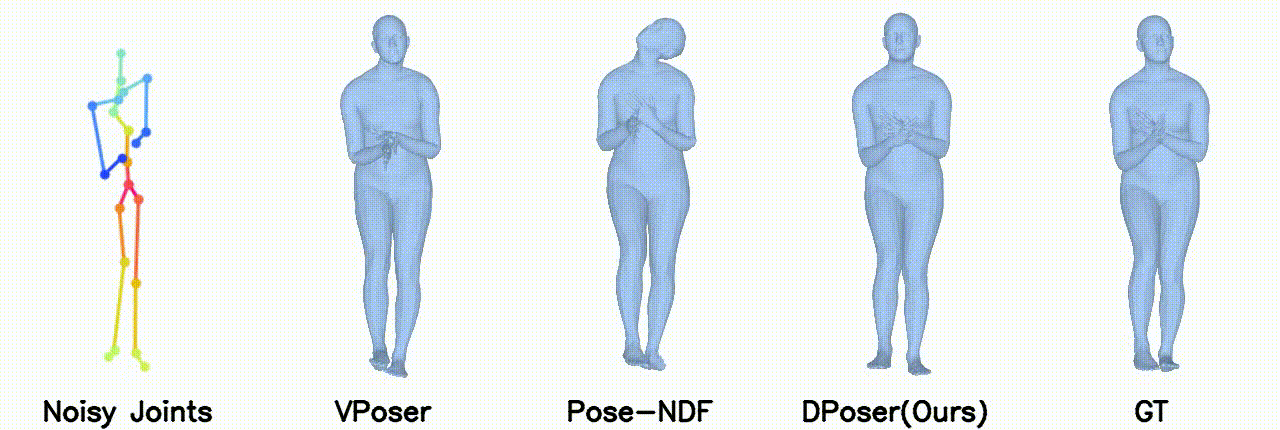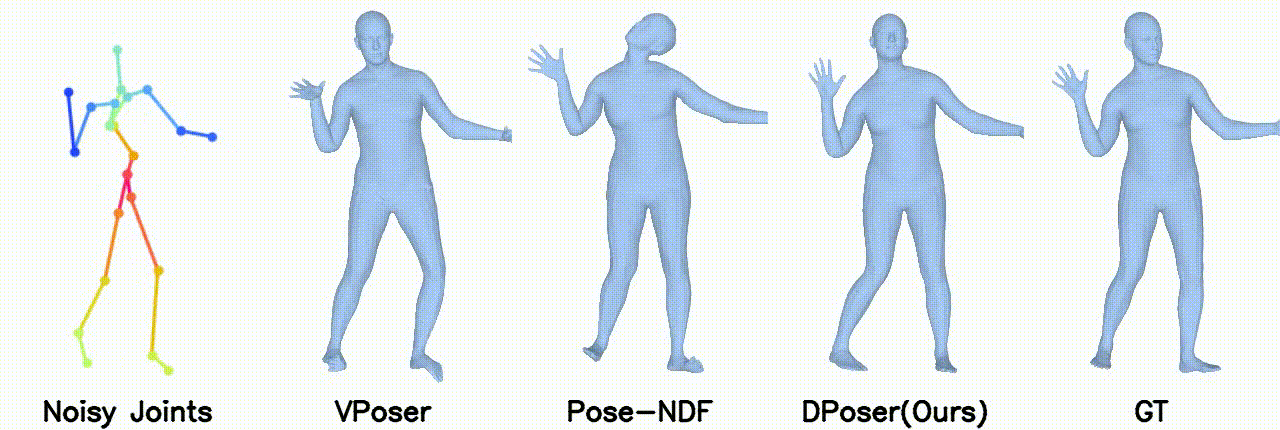
Motion Denoising
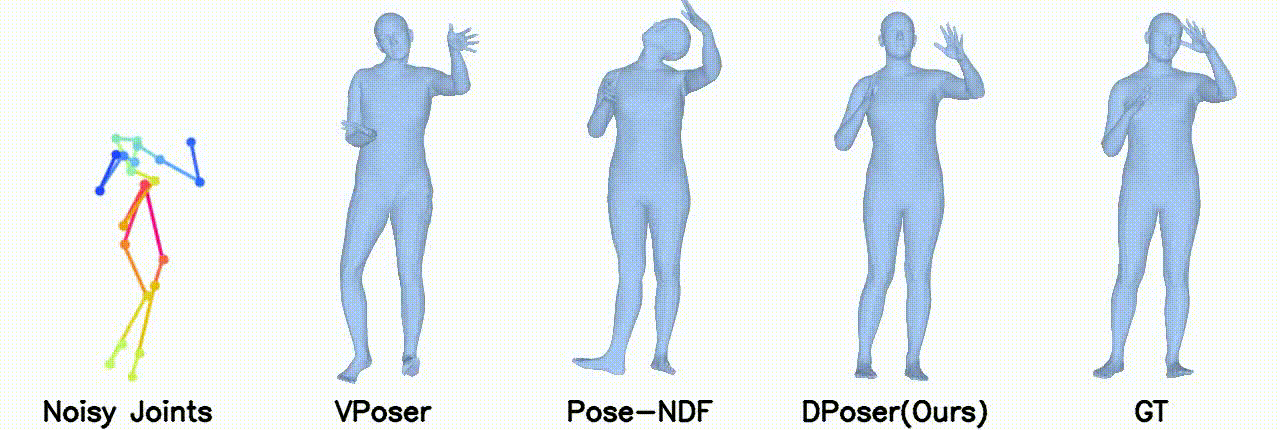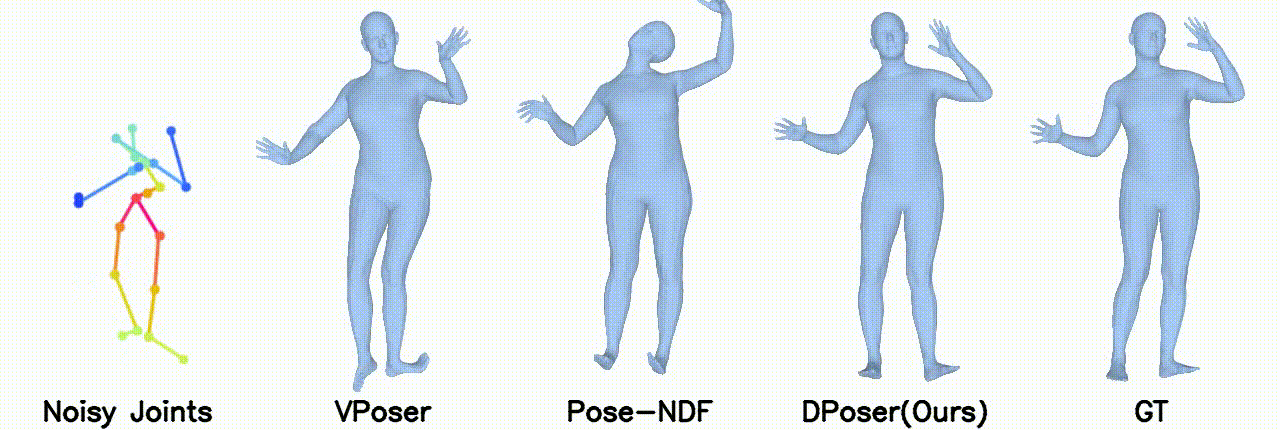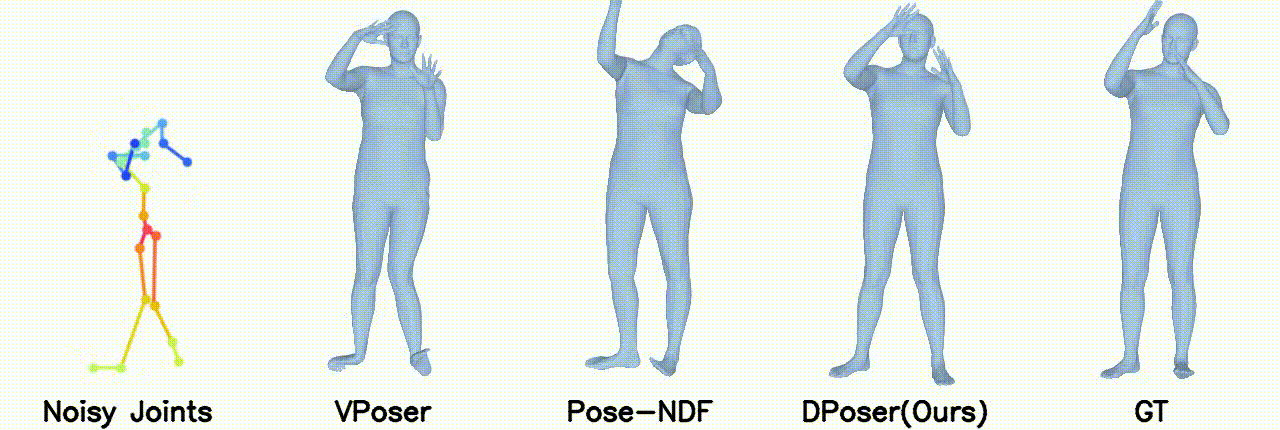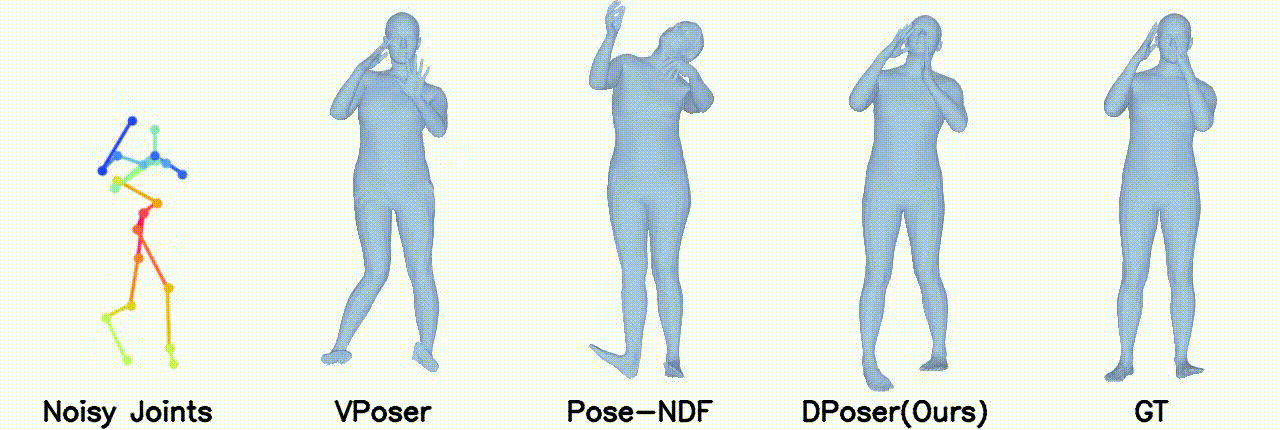
Gaussian noise with 40 mm standard deviation.
Gaussian noise with 100 mm standard deviation.
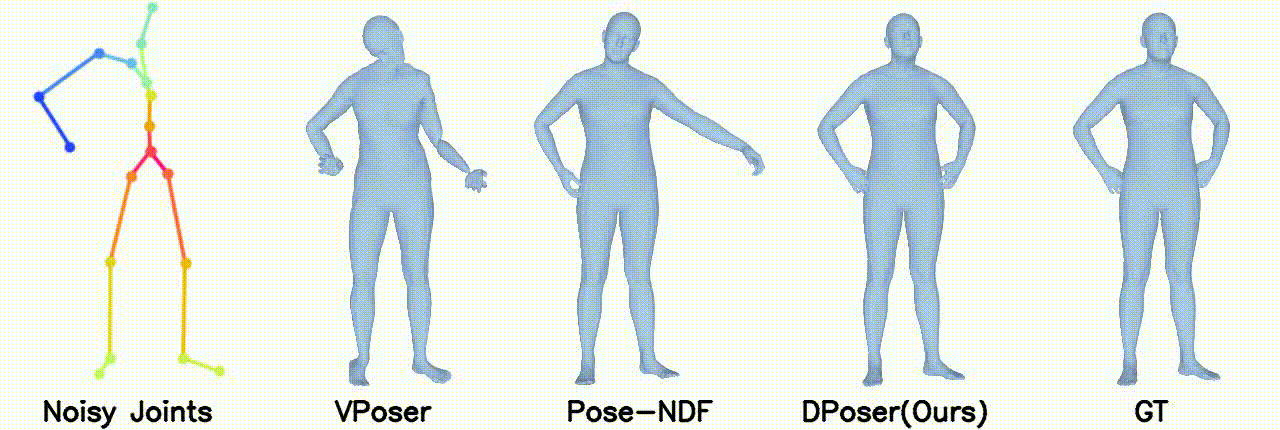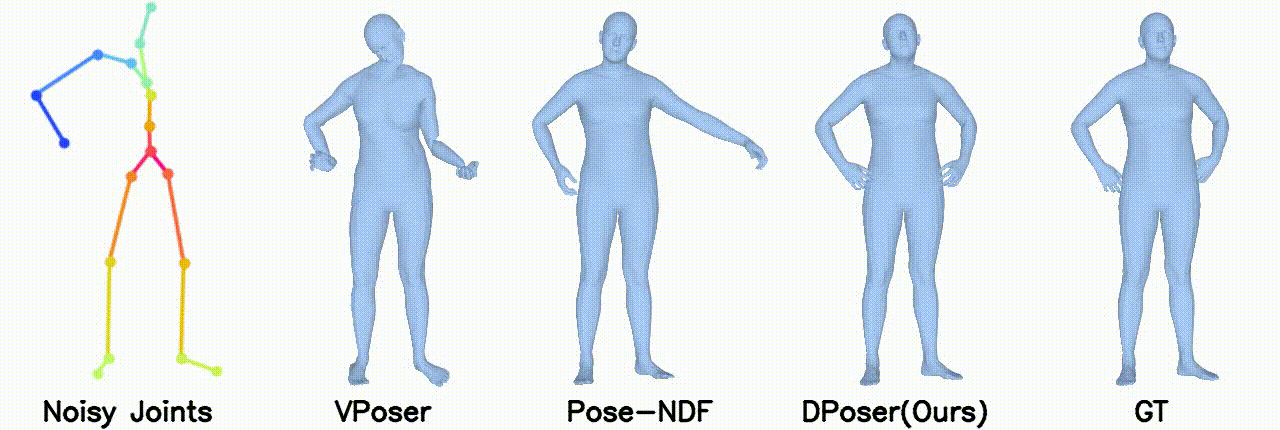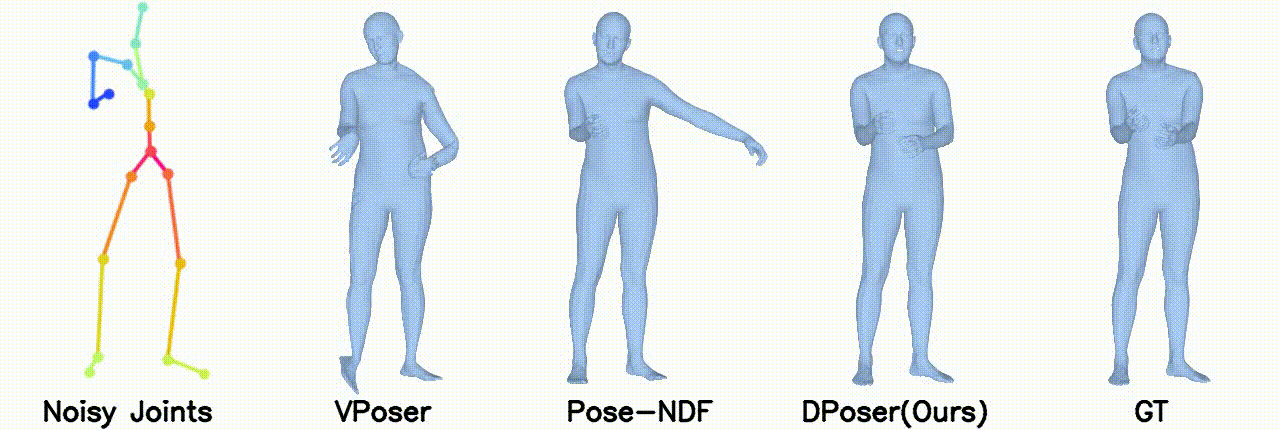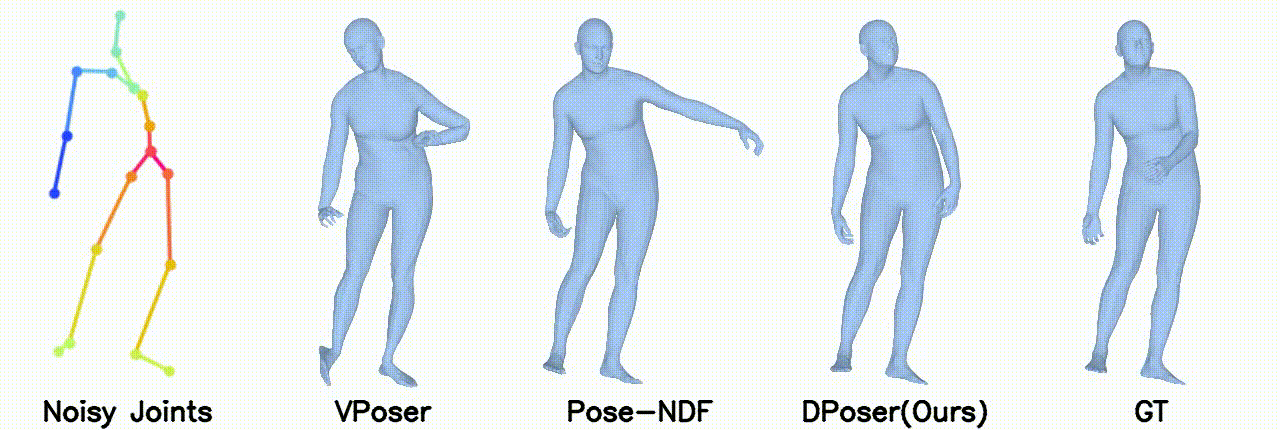
Left arm under occlusion.
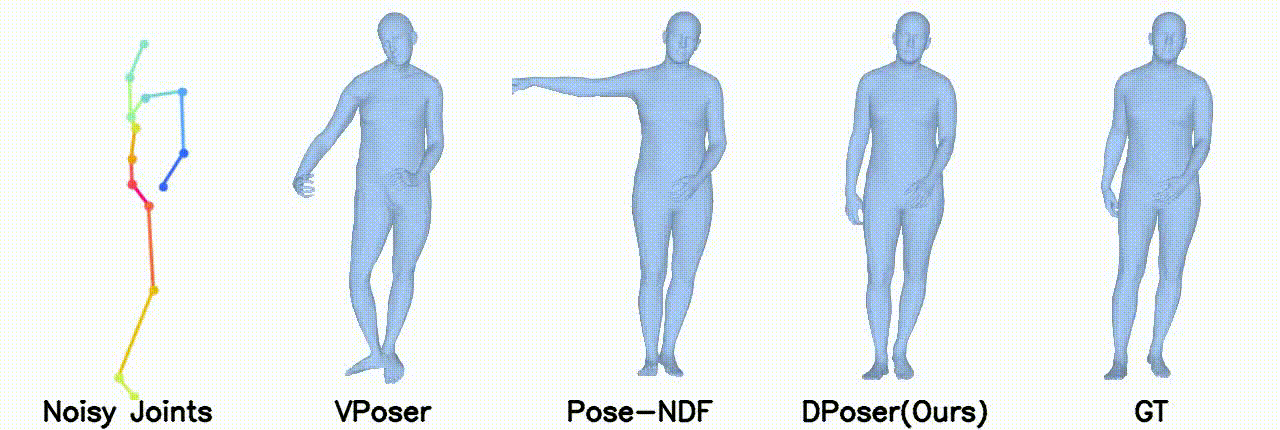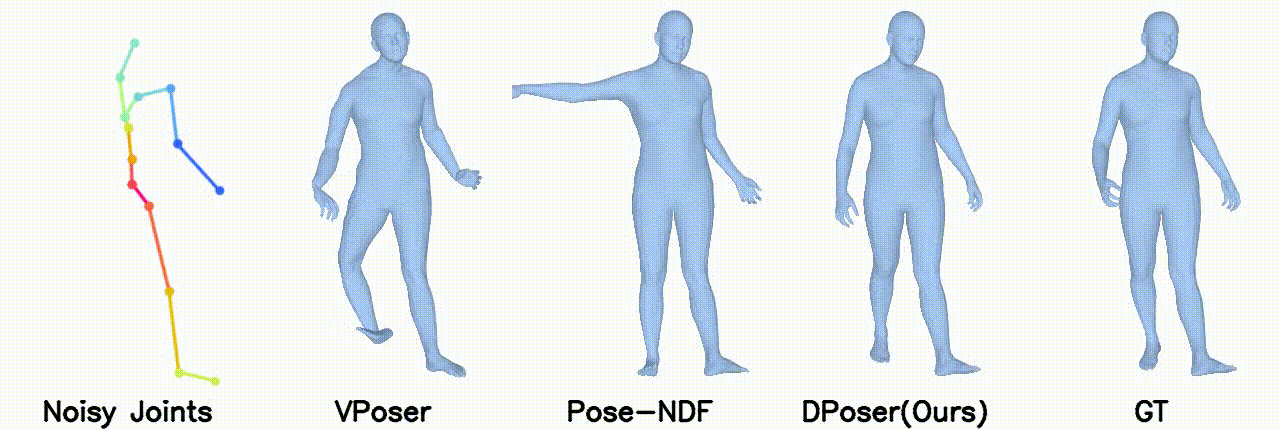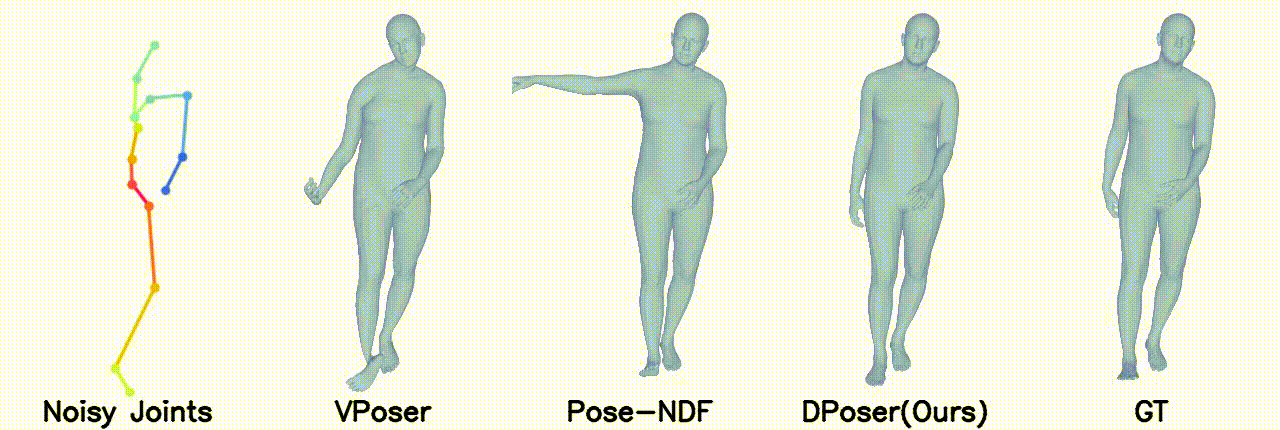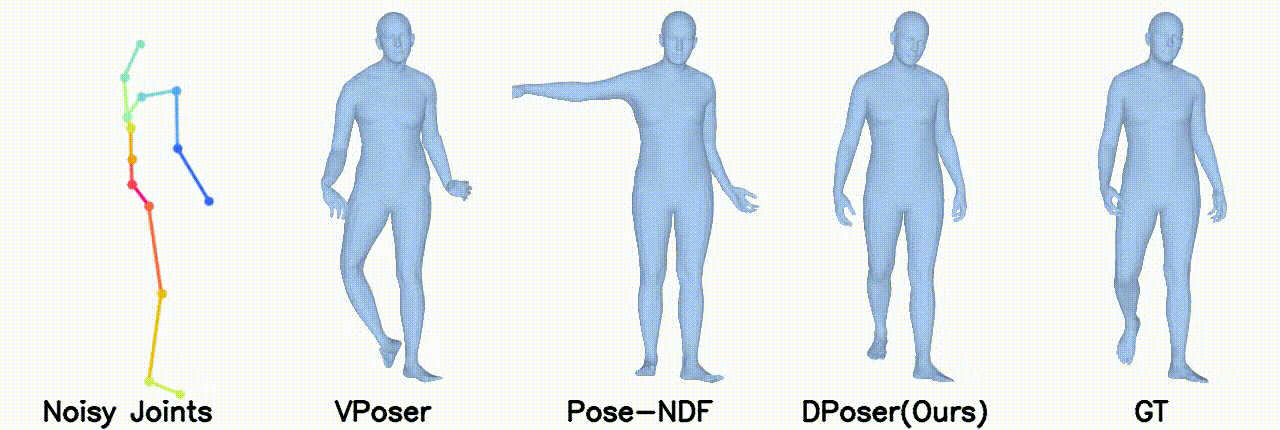
Right body occlusion.
In motion denoising, DPoser excels at reconstructing realistic pose sequences from noisy and incomplete 3D joint data, and its effectiveness as a single-frame pose prior extends well to sequences, ensuring lifelike movements.
Hand-only Tasks
Hand Pose Generation

DPoser hand pose generation.

VPoser hand pose generation.

NRDF hand pose generation.
In hand pose generation, DPoser generates a wide variety of diverse and realistic hand poses. This stands in contrast to competing methods; for instance, VPoser tends to produce poses with limited diversity, while NRDF struggles with realism.
Hand Inverse Kinematics
In hand inverse kinematics, DPoser maintains stability and precision, showcasing its superior ability to handle noisy input and recover plausible hand poses even under challenging conditions such as a) noisy keypoints, b) fingertip keypoints, c) partial finger keypoints, and d) sparse keypoints settings.
Hand Mesh Recovery

Fitting from scratch.

Initialization with Hand4Whole.
In hand mesh recovery, DPoser consistently outperforms competing methods with superior accuracy and natural hand mesh reconstruction.
Face-only Tasks
Face Generation

Face shape generation.

Facial expression generation.
In face generation, DPoser can generate a wide variety of realistic face shapes and expressions. It captures a broader range of subtle variations, especially in expressions.
Face Reconstruction
Fitting from scratch.

Initialization with MICA.
In face reconstruction, DPoser can reconstruct detailed and realistic face meshes, even in challenging scenarios with variations in side-view poses and complex expressions.
Whole-body Tasks
Whole-body Pose Generation

Mixed training strategy.

Direct training strategy.
In whole-body pose generation, DPoser-X-mixed (mixed training) generates a diverse range of whole-body poses while maintaining realistic hand interactions and facial expressions. In contrast, DPoser-X-fused (direct training) retains high realism but produces less diverse results.
Whole-body Mesh Recovery

Fitting from scratch.

Initialization with SMPLer-X.
In whole-body mesh recovery, DPoser-X outperforms other methods in handling full-body mesh recovery, demonstrating its robustness in both body and hand mesh reconstruction. It can recover plausible whole-body poses from imperfect 2D keypoints, whereas other methods struggle with noisy inputs.
Whole-body Pose Completion
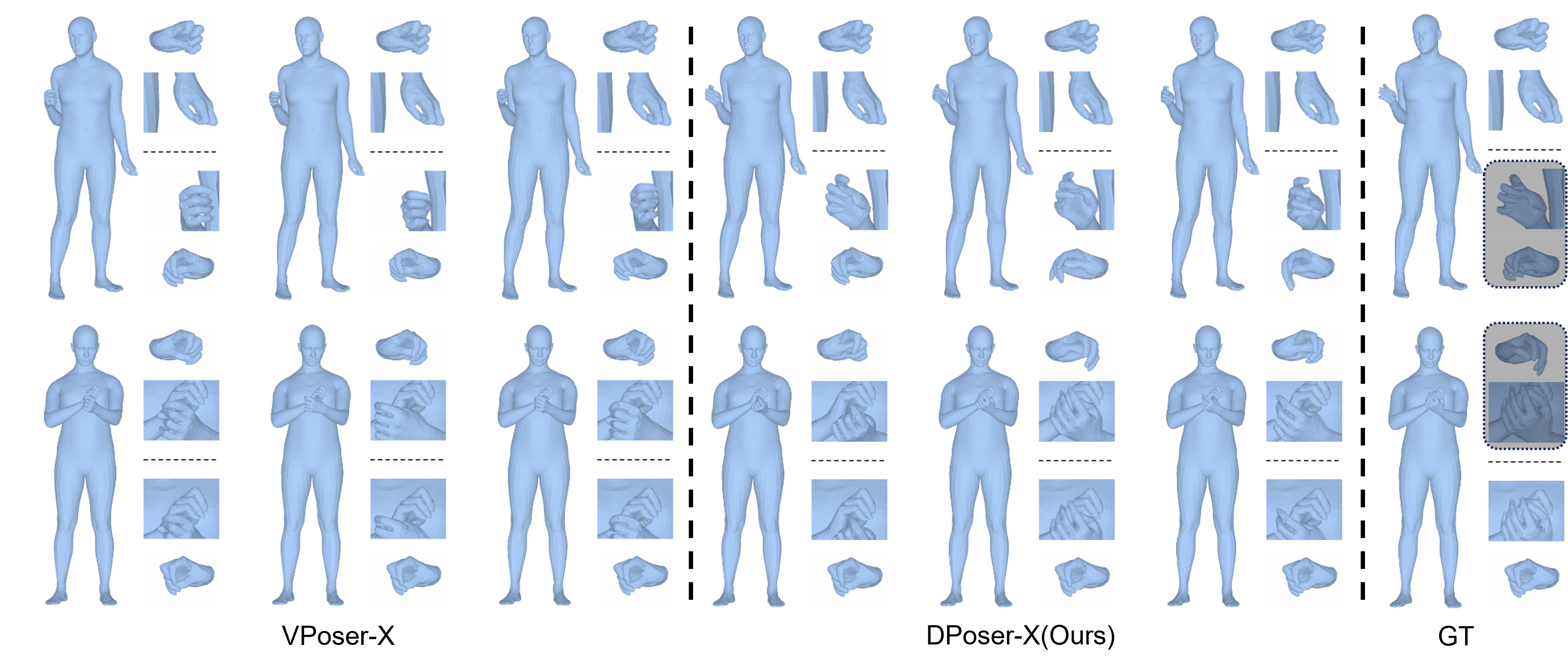
In whole-body pose completion, DPoser-X effectively learns the correlation between whole-body parts and demonstrates superior performance in completing missing body parts with natural and plausible results.
Citation
@article{lu2025dposerx,
title={DPoser-X: Diffusion Model as Robust 3D Whole-body Human Pose Prior},
author={Lu, Junzhe and Lin, Jing and Dou, Hongkun and Zeng, Ailing and Deng, Yue and Liu, Xian and Cai, Zhongang and Yang, Lei and Zhang, Yulun and Wang, Haoqian and Liu, Ziwei},
journal={arXiv preprint arXiv:2508.00599},
year={2025}
}The website template was adapted from HumanTOMATO Project.